일련의 행동을 학습하여 보상을 최적화하는 데 초점을 맞춘다.
강화학습(Reinforcement Learning, RL)
지도학습 모델은 주어진 입력 샘플에 동일한 레이블 또는 값을 할당하는 것을 학습해야 한다.
비지도학습 모델은 군집이나 차원 축소처럼 데이터셋에 내제된 구조를 학습하거나 감지하는 것이 목표이다.
(또는 훈련 데이터셋에 비슷한 분포를 가지는 새로운 합성 샘플을 생성; GAN)
강화학습은 지도학습, 비지도학습과 근본적으로 다른 세번째 부류의 머신러닝이다.
강화학습은 상호작용을 통해 학습한다.
강화학습에서 모델이 보상 함수를 최대화하기 위해 환경과 상호 작용하면서 학습한다.
보상함수의 최대화는 지도 학습에서 비용 함수를 최소화하는 개념과 관련이 있지만,
강화 학습에서는 일련의 행동을 학습하기 위한 정답 레이블을 모르며 사전에 정의되어 있지 않다.
대신 게임 승리처럼 어떤 목표를 달성하기 위해 환경과 상호 작용하면서, 학습해야 한다.
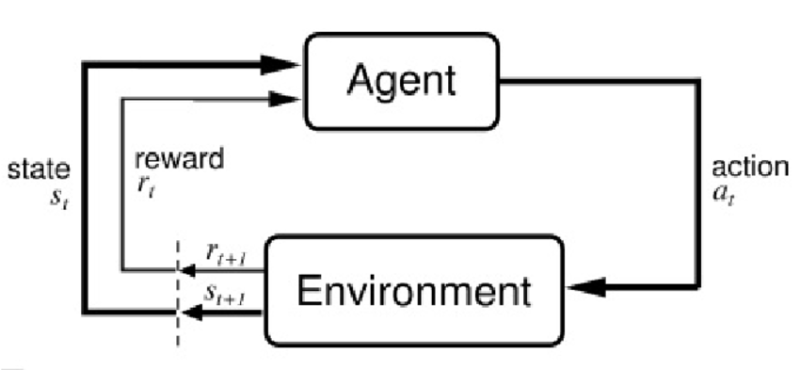
강화 학습에서 모델(agent or model)은 환경과 상호하기 위해서 일련의 행동(action)을 생성한다.
(이와 같은 행동의 모음을 에피소드(episode)라고 한다.)
상호작용을 통해서 에이전트는 환경이 제공하는 보상을 모은다.(보상은 양수 혹은 음수)
(에피소드가 끝날 때까지 보상이 에이전트에 제공되지 않을 수도 있다.)
강화 학습에서는 에이전트, 컴퓨터, 로봇에게 무엇을 하라고 가르칠 수 없다.
에이전트가 달성해야 할 것을 지정할 수 밖에 없다.
이 후, 시행착오를 통해 얻은 결과를 바탕으로 에이전트의 성공과 실패에 따라 보상을 결정할 수 있다.
ex)
체스와 같은 게임을 강화 학습으로 학습시킨다고 할 때, 체스 기물의 레이블(보상)은 게임이 끝날 때까지 알 수 없다.
컴퓨터가 게임을 이겼다면, 에이전트에게 양의 보상을 제공하고 게임에서 졌다면, 음의 보상을 제공한다.
체스는 현재 상황을 입력으로 사용한다.
가능한 입력(시스템의 개수)가 많으면, 각 상황이나 상태를 양성 또는 음성으로 레이블하기가 불가능하다.
따라서 학습 과정을 구성하기 위해 원하는 결과를 얻었는지 알 수 있는 게임 종료 후에 보상(혹은 페널티)를 제공한다.
강화 학습은 복잡한 환경에서 의상 결정할 때,
특히 알려지지 않은 일련의 단계가 문제 해결에 필요할 때 또는 설명하거나 정의하기 어려울 때 매력적인 방법이다.
강화 학습은 특정 목표를 달성하기 위해 일련의 행동을 학습할 수 있는 강력한 프레임워크를 제공한다.
하지만 강화 학습은 비교적 초기 단계이고 풀지 못한 문제가 많아 활발히 연구되는 분야이다.
강화 학습의 훈련을 힘들게 하는 한가지 문제점은 이전에 선택했던 행동에 따라 모델의 입력이 달라진다는 점이다.
이로 인해 각종 문제가 발생하고 불안정한 훈련을 야기한다.(시퀀스 의존성)
강화 학습의 시퀀스 의존성은 지연효과(delayed effect)를 만든다.
즉, 타임 스텝 t에 선택한 행동이 언제일지 모르지만, 일련의 타임 스텝 뒤에 나타난 미래 보상을 만들어 낸다.
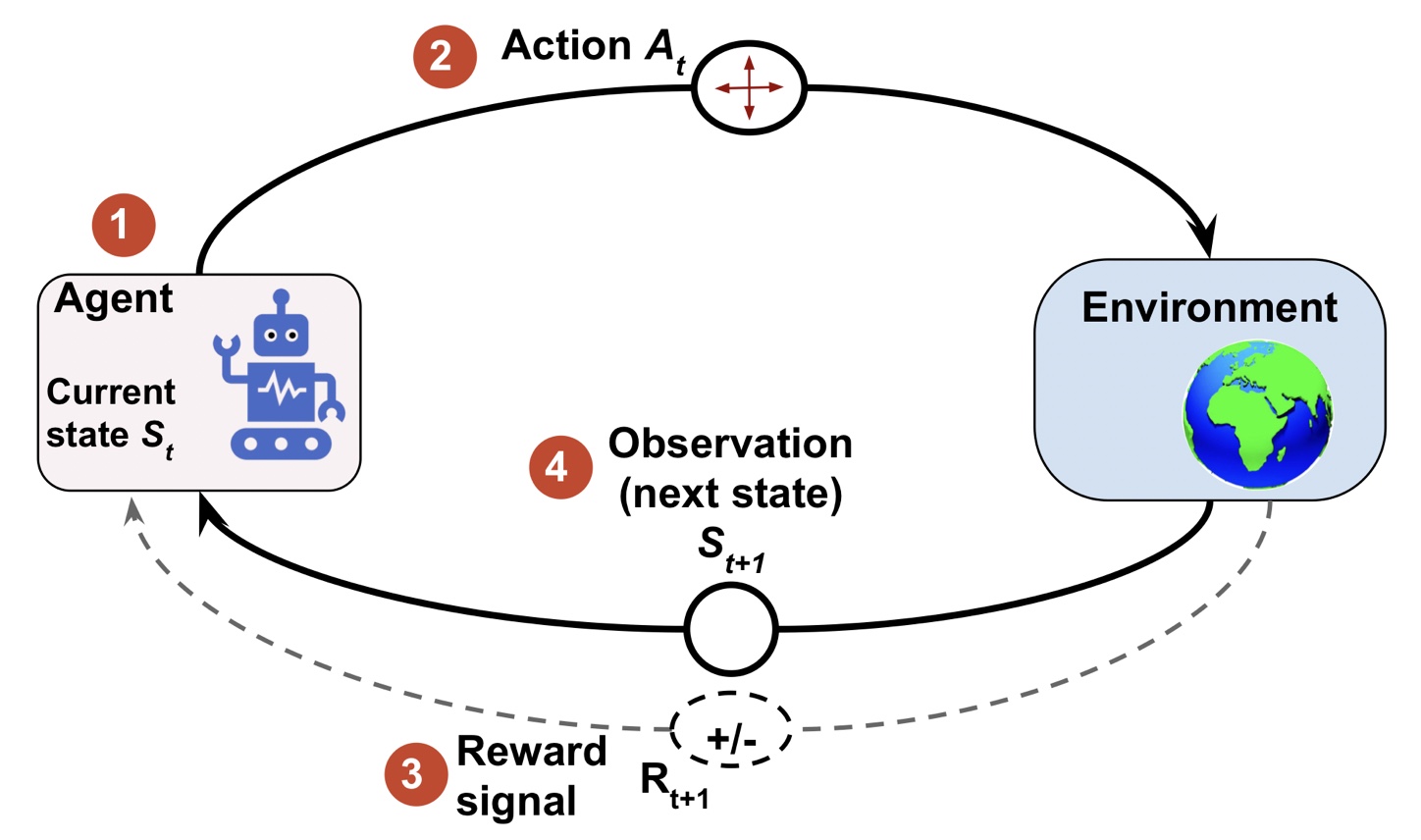
Interface of Reinforcement Learning
Agent & Environment
모든 강화 학습에는 에이전트와 환경 객체가 존재한다.
에이전트(agent)는 행동을 통해 주변 환경과 상호작용하고 의사 결정 방법을 학습하는 객체이다.
에이전트는 행동의 결과로 환경과 상호 작용하고 의사 결정 방법을 배운다.
환경(environment)은 강화학습에서 에이전트를 제외한 모든 것으로
환경은 에이전트와 통신하고 에이전트의 행동에 대한 보상 신호를 결정하고 관측 내용을 전달한다.
보상 신호(reward signal)은 에이전트가 환경과 상호 작용하면서 받는 피드백을 말한다.
보통 스칼라 값으로 제공되고 양수나 음수가 가능하다.
(보상은 에이전트가 얼마나 잘 수행했는지 알려 주는 것이 목적이다.)
에이전트가 보상을 받는 주기는 작업이나 문제에 따라 다르다.
체스 같은 경우 게임이 끝나면 보상 지급
미로 게임 같은 경우 타임 스텝마다 보상을 제공-에이전트가 에피소드 전체 기간 동안 누적된 보상을 최대화
타임 스텝마다 에이전트는 가능한 모든 행동의 집합을 통해 환경과 상호작용을 한다.
에이전트가 상태에서 선택한 행동을 기반으로 에이전트는 보상신호를 받고 상태를 업데이트
학습과정 중에 에이전트는 여러 행동을 시도해 봐야 한다.(탐험(exploration))
점진적으로 에이전트는 총 누적 보상을 최대화하기 위해 더 많이 실행되고 선호하는 행동을 학습한다.(활용(exploitation))
일반적으로 활용은 단기간 보상이 큰 행동을 선택하고, 탐험은 장기간 실행했을 때 총 보상이 더 많은 결과를 만들 수 있다.
탐험과 활용 사이의 트레이드오프는 광범위하게 연구되고 있지만, 아직 이 의사 결정 딜레마에 대한 보편적인 해답은 없음